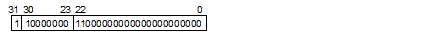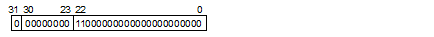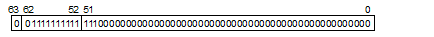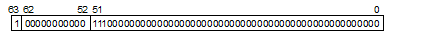本節では、型名と、データの内部表現の対応について述べます。データの内部表現は、以下の項目から成り立っています。
データの占有する領域のサイズです。
データを割り付けるアドレスに関する制約です。任意のアドレスに割り付ける1バイトアライメント、偶数バイトに割り付ける2バイトアライメント、4の倍数バイトに割り付ける4バイトアライメントがあります。
スカラ型(C言語)、基本型(C++言語)の値のとり得る範囲を示します。
構造体/共用体(C言語)、クラス型(C++言語)の要素となるデータの割り付け方を示します。
C言語におけるスカラ型および、C++言語における基本型の内部表現を表 4.1に示します。
|
|
|
|
|
|
|
|
|
|
|
1
|
char *1
|
1
|
1
|
無
|
0
|
28-1 (255)
|
|
2
|
signed char
|
1
|
1
|
有
|
-27 (-128)
|
27-1 (127)
|
|
3
|
unsigned char
|
1
|
1
|
無
|
0
|
28-1 (255)
|
|
4
|
short
|
2
|
2
|
有
|
-215 (-32768)
|
215-1 (32767)
|
|
5
|
signed short
|
2
|
2
|
有
|
-215 (-32768)
|
215-1 (32767)
|
|
6
|
unsigned short
|
2
|
2
|
無
|
0
|
216-1 (65535)
|
|
7
|
int *2
|
4
|
4
|
有
|
-231(-2147483648)
|
231-1 (2147483647)
|
|
8
|
signed int *2
|
4
|
4
|
有
|
-231(-2147483648)
|
231-1 (2147483647)
|
|
9
|
unsigned int *2
|
4
|
4
|
無
|
0
|
232-1 (4294967295)
|
|
10
|
long
|
4
|
4
|
有
|
-231
(-2147483648)
|
231-1 (2147483647)
|
|
11
|
signed long
|
4
|
4
|
有
|
-231
(-2147483648)
|
231-1 (2147483647)
|
|
12
|
unsigned long
|
4
|
4
|
無
|
0
|
232-1 (4294967295)
|
|
13
|
long long
|
8
|
4
|
有
|
-263
(-9223372036854775808)
|
263-1
(9223372036854775807)
|
|
14
|
signed long long
|
8
|
4
|
有
|
-263
(-9223372036854775808)
|
263-1
(9223372036854775807)
|
|
15
|
unsigned long long
|
8
|
4
|
無
|
0
|
264-1
(18446744073709551615)
|
|
16
|
float
|
4
|
4
|
有
|
-∞
|
+∞
|
|
17
|
double
long double
|
4 *4
|
4
|
有
|
-∞
|
+∞
|
|
18
|
size_t
|
4
|
4
|
無
|
0
|
232-1 (4294967295)
|
|
19
|
ptrdiff_t
|
4
|
4
|
有
|
-231
(-2147483648)
|
231-1 (2147483647)
|
|
20
|
enum *3
|
4
|
4
|
有
|
-231
(-2147483648)
|
231-1 (2147483647)
|
|
21
|
ポインタ
|
4
|
4
|
無
|
0
|
232-1 (4294967295)
|
|
22
|
bool *5
_Bool *8
|
1 *9
|
1 *9
|
-*9
|
-
|
-
|
|
23
|
リファレンス*6
|
4
|
4
|
無
|
0
|
232-1 (4294967295)
|
|
24
|
データメンバへのポインタ *6
|
4
|
4
|
無
|
0
|
232-1 (4294967295)
|
|
25
|
関数メンバへのポインタ *6 *7
|
12
|
4
|
- *10
|
-
|
-
|
注 1. | signed_charオプションを指定した場合、signed char型と同じ値の範囲を持ちます。 |
注 2. | int_to_shortオプションを指定した場合、int型はshort型と、signed int型はsigned short型と、unsigned int型はunsigned short型とそれぞれ同じ値の範囲を持ちます。 |
注 3. | auto_enumオプションを指定した場合、列挙値が収まる最小の型となります。 |
注 4. | dbl_size=8を指定した場合、double型およびlong double型のサイズは8バイトになります。 |
注 5. | C++プログラム、またはstdbool.hをインクルードしたCプログラムのコンパイル時のみ有効です。 |
注 6. | C++プログラムのコンパイル時のみ有効です。 |
注 7. | 関数メンバ・仮想関数メンバへのポインタは、以下のデータ構造で表現しています。 |
class PMF{
public:
long d; // オブジェクトのオフセット値
long i; // 対象メンバ関数が仮想関数のときの仮想関数表中での
// インデックス
union{
void (*f)(); // 対象メンバ関数が非仮想関数のときの関数のアドレス
long offset; // 対象メンバ関数が仮想関数のときの仮想関数表のオブジェクト
// 中のオフセット
};
};
|
注 8. | C99コンパイル、またはstdbool.hをインクルードしたCプログラムのコンパイル時に有効です。 |
注 9. | C89でコンパイルする場合は、unsigned long型と同じサイズ、アライメント数及び符号になります。 |
(2) | 構造体/共用体(C言語)、クラス型(C++言語) |
本項では、C言語における配列型、構造体型、共用体型および、C++言語におけるクラス型の内部表現について説明します。
表 4.2に構造体/共用体、クラス型の内部表現を示します。
|
|
|
|
|
|
|
1
|
配列型
|
配列要素のアライメント数
|
配列要素の数×要素サイズ
|
char a[10]; アライメント数 1byte
サイズ 10byte
|
|
2
|
構造体型
|
構造体メンバのアライメント数のうち最大値
|
メンバのサイズの和
「(a) 構造体データの割り付け方」参照
|
struct { アライメント数 1byte
char a,b; サイズ 2byte
};
|
|
3
|
共用体型
|
共用体メンバのアライメント数のうち最大値
|
最大メンバのサイズ
「(b) 共用体データの割り付け方」参照
|
union { アライメント数 1byte
char a,b; サイズ 1byte
};
|
|
4
|
クラス型
|
仮想関数がある場合:
常に4
2)上記以外:
データメンバのアライメント数のうち最大値
|
データメンバ、仮想関数表へのポインタ、仮想基底クラスへのポインタの和
「(c) クラスデータの割り付け方」参照
|
class B: public A{
virtual void f(); アライメント数 4byte
}; サイズ 8byte
class A{
char a; アライメント数 1byte
}; サイズ 1byte
|
以下の例でサイズを明記していない  は、4バイトを表します。
は、4バイトを表します。  はパディングを表します。
はパディングを表します。
また、アドレスの増える向きは、右から左とします(左側が上位アドレス)。
構造体型の各メンバを割り付ける場合、そのメンバの型名の境界調整数に合わせるために直前のメンバとの間にパディングが生じる場合があります。
struct {
char a;
int b;
} obj;
|
構造体が4バイトのアライメント数を持ち、最後のメンバが1,2,3バイト目で終わっている場合、その次のバイトも含めて構造体型の領域として扱います。
struct {
int a;
char b;
} obj;
|
共用体が4バイトのアライメント数を持ち、最大メンバのサイズが4の倍数バイトでない場合、4の倍数になるまで残りのバイトも含めて共用体型の領域として扱います。
union {
int a;
char b[7];
} o;
|
基底クラス、仮想関数がないクラスの場合、構造体データの割り付け規則に従ってデータメンバを割り付けます。
class A{
char data1;
int data2;
public:
A();
char getData1(){return data1;}
}obj;
|
アライメント数が1の基底クラスから派生したクラスの先頭メンバが1byteデータの場合、パディングを作らないようにデータメンバを割り付けます。
class A{
char data1;
};
class B:public A{
char data2;
short data3;
}obj;
|
クラスに仮想基底クラスがある場合、仮想基底クラスへのポインタを割り付けます。
class A{
short data1;
};
class B: virtual protected A{
char data2;
}obj;
|
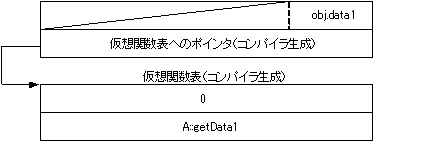
クラスに仮想関数がある場合、コンパイラは仮想関数表を生成し、仮想関数表へのポインタを割り付けます。
class A{
char data1;
public:
virtual char getData1();
}obj;
|
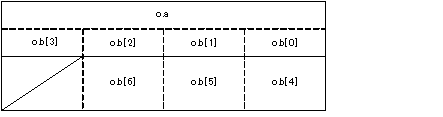
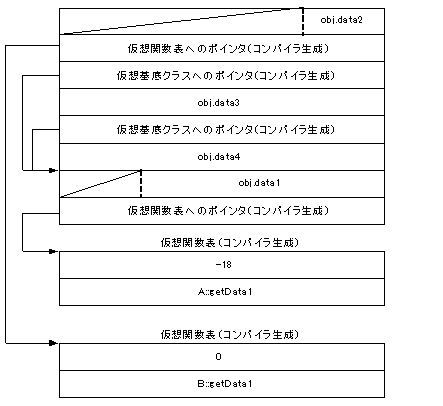
仮想基底クラス、基底クラス、仮想関数があるクラスの例を示します。
class A{
char data1 ;
virtual char getData1();
};
class B:virtual public A{
char data2;
char getData2();
char getData1();
};
class C:virtual protected A{
int data3;
};
class D:virtual public A,public B,public C{
public:
int data4;
char getData1();
}obj;
|
空クラスの場合、1バイトのダミー領域を割り付けます。
class A{
void fun();
}obj;
|
空クラスを基底クラスに持つ空クラスの場合でも、ダミー領域は1バイトになります。
class A{
void fun();
};
class B: A{
void sub();
}obj;
|
空クラスのダミー領域は、クラスサイズが0の場合に割り付けます。基底クラスや派生クラスにデータメンバがある場合や、仮想関数があるクラスの場合には、ダミー領域は割り付けません。
class A{
void fun();
};
class B: A{
char data1;
}obj;
|
ビットフィールドは、構造体、共用体、クラスの中にビット幅を指定して割り付けるメンバです。
本項では、ビットフィールド特有の割り付け規則について説明します。
表 4.3にビットフィールドメンバの仕様を示します。
|
|
|
|
|
1
|
ビットフィールドで許される型指定子
|
(unsigned) char、signed char、bool*1、_Bool*5、
(unsigned) short、signed short、enum、
(unsigned) int、signed int、
(unsigned) long、signed long、
(unsigned) long long、signed long long
|
|
2
|
宣言された型に拡張するときの符号の扱い*2
|
符号なし(unsigned)は、ゼロ拡張*3
符号付き(signed)は、符号拡張*4
|
|
3
|
符号指定なしの型の符号型
|
符号なし(unsigned)
但し、signed_bitfieldオプションが指定された場合は、符号付き(signed)
|
|
4
|
enum型の符号型
|
符号付き (signed)
但し、auto_enumオプションが指定された場合は、その結果の型に従う
|
注 1. | C++プログラム、またはstdbool.hをインクルードしたCプログラムのコンパイル時のみboolを指定できます。 |
注 2. | ビットフィールドのメンバを使用する場合、ビットフィールドに格納したデータを宣言した型に拡張して使用します。符号付き(signed)で宣言されたサイズが1ビットのビットフィールドのデータは、データそのものを符号として解釈します。したがって、表現できる値は0と-1だけになります。 |
注 3. | ゼロ拡張:拡張するときに上位のビットにゼロを補います。 |
注 4. | 符号拡張:拡張するときにビットフィールドデータの最上位ビットを符号として解釈し、データより上位のビット全てに符号ビットを補います。 |
注 5. | C99プログラムのみ有効です。_Bool型はbool型と同じ型としてコンパイルされます。 |
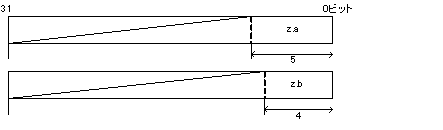
ビットフィールドは、以下の5つの規則に従って割り付けます。
- | ビットフィールドのメンバは領域内で右(下位ビット側)から順に詰め込みます。 |
struct b1 {
int a:2;
int b:3;
} x;
|
- | 同じサイズの型指定子が連続している場合は、可能な限り同じ領域に詰め込みます。 |
struct b1 {
long a:2;
unsigned int b:3;
} y;
|
異なるサイズの型指定子で宣言されたメンバは、次の領域に割り付けます。
struct b1 {
int a:5;
char b:4;
} z;
|
- | 同じサイズの型指定子が連続していても、詰め込み先の領域の残りビットが、次のビットフィールドのサイズより小さい場合は、残りの領域は未使用領域となり、次の領域に割り付けます。 |
struct b2 {
char a:5;
char b:4;
} v;
|
- | ビット幅0のビットフィールドのメンバを指定すると、次のメンバからは、強制的に次の領域に割り付けます。 |
struct b2 {
char a:5;
char :0;
char c:3;
} w;
|
備考 | ビットフィールドメンバを上位ビット側から詰め込むことも可能です。
詳細は、「4.2 拡張言語仕様」の#pragma bit_orderおよび「オプション」の章のbit_orderオプションを参照してください。 |
Big Endianでのメモリ上のデータ配列は以下のとおりです。
(a) | 1バイトデータ(char、signed char、unsigned char、bool*1、_Bool*1型) |
1バイトデータの中のビット並び順は、Little Endianの場合も、Big Endianの場合も同じです。
注 1. | C89でコンパイルする場合は、サイズ、アライメント数共に4になります。 |
(b) | 2バイトデータ((signed )short、unsigned short型) |
2バイトデータの中のバイト並び順は、Little EndianとBig Endianで上位、下位のバイトが逆になります。
0x100番地に2バイトデータ0x1234がある場合
Little Endian: 0x100番地:0x34 Big Endian: 0x100番地:0x12
0x101番地:0x12 0x101番地:0x34
(c) | 4バイトデータ((signed )int*2、unsigned int*2、(signed )long、unsigned long、float型) |
4バイトデータの中のバイト並び順は、Little EndianとBig Endianで4バイトのデータの順序が逆になります。
注 2. | int_to_shortオプションを指定した場合、signed int型はsigned short型と、unsigned int 型はunsigned short型とそれぞれ同じサイズ及びアライメント数になります。 |
0x100番地に4バイトデータ0x12345678がある場合
Little Endian: 0x100番地:0x78 Big Endian: 0x100番地:0x12
0x101番地:0x56 0x101番地:0x34
0x102番地:0x34 0x102番地:0x56
0x103番地:0x12 0x103番地:0x78
(d) | 8バイトデータ((signed )long long、unsigned long long、double型) |
8バイトデータの中のバイト並び順は、Little EndianとBig Endianで8バイトのデータの順序が逆になります。
0x100番地に8バイトデータ0x0123456789abcdefがある場合
Little Endian: 0x100番地:0xef Big Endian: 0x100番地:0x01
0x101番地:0xcd 0x101番地:0x23
0x102番地:0xab 0x102番地:0x45
0x103番地:0x89 0x103番地:0x67
0x104番地:0x67 0x104番地:0x89
0x105番地:0x45 0x105番地:0xab
0x106番地:0x23 0x106番地:0xcd
0x107番地:0x01 0x107番地:0xef
構造体/共用体、クラス型データの各メンバの割り付けはLittle Endianのときと同様です。ただし、各メンバのバイト並び順はそのデータサイズの規則に従って反転します。
0x100番地に、
struct {
short a;
int b;
}z = {0x1234, 0x56789abc};
がある場合
Little Endian: 0x100番地:0x34 Big Endian: 0x100番地:0x12
0x101番地:0x12 0x101番地:0x34
0x102番地:パディング 0x102番地:パディング
0x103番地:パディング 0x103番地:パディング
0x104番地:0xbc 0x104番地:0x56
0x105番地:0x9a 0x105番地:0x78
0x106番地:0x78 0x106番地:0x9a
0x107番地:0x56 0x107番地:0xbc
ビットフィールドの各領域の割り付けもLittle Endianのときと同様です。ただし、各領域のバイト並び順はそのデータサイズの規則に従って反転します。
0x100番地に、
struct {
long a:16;
unsigned int b:15;
short c:5;
}y={1,1,1};
がある場合
Little Endian: 0x100番地:0x01 Big Endian: 0x100番地:0x00
0x101番地:0x00 0x101番地:0x01
0x102番地:0x01 0x102番地:0x00
0x103番地:0x00 0x103番地:0x01
0x104番地:0x01 0x104番地:0x00
0x105番地:0x00 0x105番地:0x01
0x106番地:パディング 0x106番地:パディング
0x107番地:パディング 0x107番地:パディング
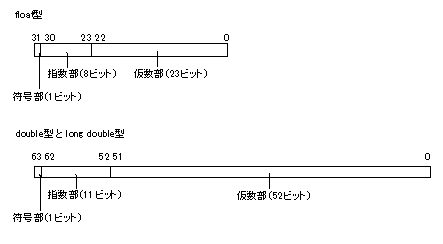
コンパイラで扱う浮動小数点型の内部表現は、IEEEの形式に準拠しています。ここでは、IEEE形式の浮動小数点型の内部表現の概要について述べます。
なお、本節ではdbl_size=8オプションが指定されたものとして説明しています。dbl_size=4オプションが指定された場合は、double型およびlong double型の内部表現は、float型と同じになります。
float型はIEEEの単精度形式(32ビット)、double型とlong double型はIEEEの倍精度形式(64ビット)で表現します。
float型およびdouble型とlong double型の浮動小数点データフォーマットを図 4.1に示します。
内部表現の各構成要素の意味を以下に示します。
(i) 符号部
浮動小数点型の符号を示します。0のとき正、1のとき負を示します。
(ii) 指数部
浮動小数点型の指数を2のべき乗で示します。
(iii) 仮数部
浮動小数点型の有効数字に対応するデータです。
浮動小数点型は、通常の実数値のほかに、無限大等の値も表現することができます。浮動小数点型が表現する値の種類を以下に示します。
(i) 正規化数
指数部が0または全ビット1ではない場合です。通常の実数値を表現します。
(ii) 非正規化数
指数部が0で、仮数部が0でない場合です。絶対値の小さな実数値を表現します。
(iii) ゼロ
指数部および仮数部が0の場合です。値0.0を表現します。
(iv) 無限大
指数部が全ビット1で仮数部が0の場合です。無限大を表現します。
(v) 非数
指数部が全ビット1で仮数部が0でない場合です。「0.0/0.0」、「∞/∞」、「∞-∞」等、結果が数値に対応しない演算の結果として得られます。
浮動小数点型の表現する値を決定する条件を表 4.4に示します。
|
|
|
|
|
|
|
|
0
|
0
|
正規化数
|
無限大
|
|
0以外
|
非正規化数
|
非数
|
注 | 非正規化数は、正規化数で表現できない範囲の絶対値の小さな浮動小数点型を表現しますが、正規化数と比較して有効桁数が少なくなっています。したがって、演算の結果あるいは途中結果が非正規化数となる場合、結果の有効桁数は保証しません。
denormalize=offを指定した場合、非正規化数は0として扱います。
denormalize=onを指定した場合、非正規化数は非正規化数のまま扱います。 |
float型の内部表現は、1ビットの符号部、8ビットの指数部、23ビットの仮数部からなります。
(i) 正規化数
符号部は、0(正)または1(負)で、値の符号を示します。
指数部は、1~254(28-2)の値をとります。実際の指数は、この値から127を引いた値で、その範囲は-126~127です。
仮数部は、0~223-1の値をとります。実際の仮数は、223のビットを1と仮定し、その直後に小数点があるものとして解釈します。
正規化数の表現する値は、
(-1)<符号部> × 2<指数部>-127 ×(1 + <仮数部> × 2-23)
となります。
符号:-
指数:10000000(2) - 127 = 1 (2)は2進数を意味します。
仮数:1.11(2) = 1.75
値: -1.75 × 21 = -3.5
(ii) 非正規化数
符号部は0(正)または1(負)で、値の符号を示します。
指数部は0で、実際の指数は-126になります。
仮数部は、1~223-1で、実際の仮数は、223のビットを0と仮定し、その直後に小数点があるものとして解釈します。
非正規化数の表現する値は、
(-1)<符号部> × 2-126 × (<仮数部> × 2-23)
となります。
符号:+
指数:-126
仮数:0.11(2) = 0.75 (2)は2進数を意味します。
値: 0.75 × 2-126
(iii) ゼロ
符号部は0(正)または1(負)で、それぞれ+0.0、-0.0を示します。
指数部、仮数部はともに0です。
+0.0、-0.0は、ともに値としては0.0を示します。
(iv) 無限大
符号部は0(正)または1(負)で、それぞれ+∞、-∞を示します。
指数部は255(28-1)です。
仮数部は0です。
(v) 非数
指数部は255(28-1)です。
仮数部は0以外の値です。
注 | 仮数部の最上位ビットが1の非数をqNaN、仮数部の最上位ビットが0の非数をsNaNと呼びます。その他の仮数フィールドの値、および符号部については規定していません。 |
double型とlong double型の内部表現は、1ビットの符号部、11ビットの指数部、52ビットの仮数部からなります。
(i) 正規化数
符号部は0(正)または1(負)で、値の符号を示します。
指数部は、1~2046(211-2)の値をとります。実際の指数は、この値から1023を引いた値で、その範囲は-1022~1023です。
仮数部は、0~252-1の値となります。実際の仮数は、252のビットを1と仮定し、その直後に小数点があるものとして解釈します。
正規化数の表現する値は、
(-1)<符号部> × 2<指数部>-1023 × (1 + <仮数部> × 2-52)
となります。
符号:+
指数:1111111111(2) - 1023 = 0 (2)は2進数を意味します。
仮数:1.111(2) = 1.875
値: 1.875 × 20 = 1.875
(ii) 非正規化数
符号部は0(正)または1(負)で、値の符号を示します。
指数部は0で、実際の指数は-1022になります。
仮数部は、1~252-1で、実際の仮数は、252のビットを0と仮定し、その直後に小数点があるものとして解釈します。
非正規化数が表現する値は、
(-1)<符号部> × 2-1022 × (<仮数部> × 2-52)
となります。
符号:-
指数:-1022
仮数:0.111(2) = 0.875 (2)は2進数を意味します。
値: 0.875 × 2-1022
(iii) ゼロ
符号部は0(正)または1(負)で、それぞれ+0.0、-0.0を示します。
指数部、仮数部はともに0です。
+0.0、-0.0は、ともに値としては0.0を示します。
(iv) 無限大
符号部は0(正)または1(負)で、それぞれ+∞、-∞を示します。
指数部は2047(211-1)です。
仮数部は0です。
(v) 非数
指数部は2047(211-1)です。
仮数部は0以外の値です。
例 | 仮数部の最上位ビットが1の非数をqNaN、仮数部の最上位ビットが0の非数をsNaNと呼びます。その他の仮数フィールドの値、および符号部については規定していません。 |